
May 24, 2023
Building Cloud Dev Assistants with GPT-4 and Pinecone on Gitpod
GPT-4 has been a massive breakthrough for the power of Large Language Models (LLMs).
For the first time, a language model has demonstrated an ability to “solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting.” Even more surprising still, it’s performance is close to human-level performance.
Given such a powerful, new tool, the first question raised is, “How can I harness it?” Today we’ll take a look at some of the ways GPT-4 can be used within a secure cloud development environment (Gitpod) to augment and improve the productivity of developers.
tldr; Take me to the Github repo
Using GPT-4 for Augmented Software Development

GPT-4 uses a natural language interface for its API calls. It also uses what’s called a system role for telling the language model the identity to assume when answering questions.
The system query is a place for you to tell the language model how you’d like your responses made. Here you can suggest things like “respond using only code”, or “respond as an experienced frontend developer”.
According to Andrej Karpathy in his new Microsoft Build talk, we need to ensure that we tell our language model to assume the identity of an expert, because it’s been trained on data from non-experts, and can’t really know that expert level answers are what we want unless we tell it.
A minimal program to query GPT-4 using OpenAI’s API looks like the following (you’ll need API access to GPT-4, which is still in beta):

 language:
language: import os
import openai
from rich import print
# have this environment variable set
openai.api_key = os.getenv("OPENAI_API_KEY")
messagesList = []
print("Enter your system prompt context below. As an example it should be something like: \n'you are an experienced frontend developer who cares about readability'")
system_prompt = input("Leave blank for default: ")
if system_prompt == "":
system_prompt = "you are an experienced frontend developer who cares deeply about code readability"
messagesList.append({"role": "system", "content": system_prompt})
first_prompt = input("Enter your prompt: ")
messagesList.append({"role": "user", "content": first_prompt})
response = openai.ChatCompletion.create(model="gpt-4", messages=messagesList)
resContent = response["choices"][0]["message"]["content"]
print(resContent)This code takes in an environment variable named OPENAI_API_KEY, and uses it to authenticate with the OpenAI API.
With this code, we can then do the following in a bash session on Gitpod:
language: $ python3 playground.py
Enter your system prompt context below. As an example it should be something like:
'you are an experienced frontend developer who cares about readability'
Leave blank for default:
Enter your prompt: write a fastapi api to handle sso logins and image uploads to s3And after a few minutes, we get the following, (mostly correct!) answer:
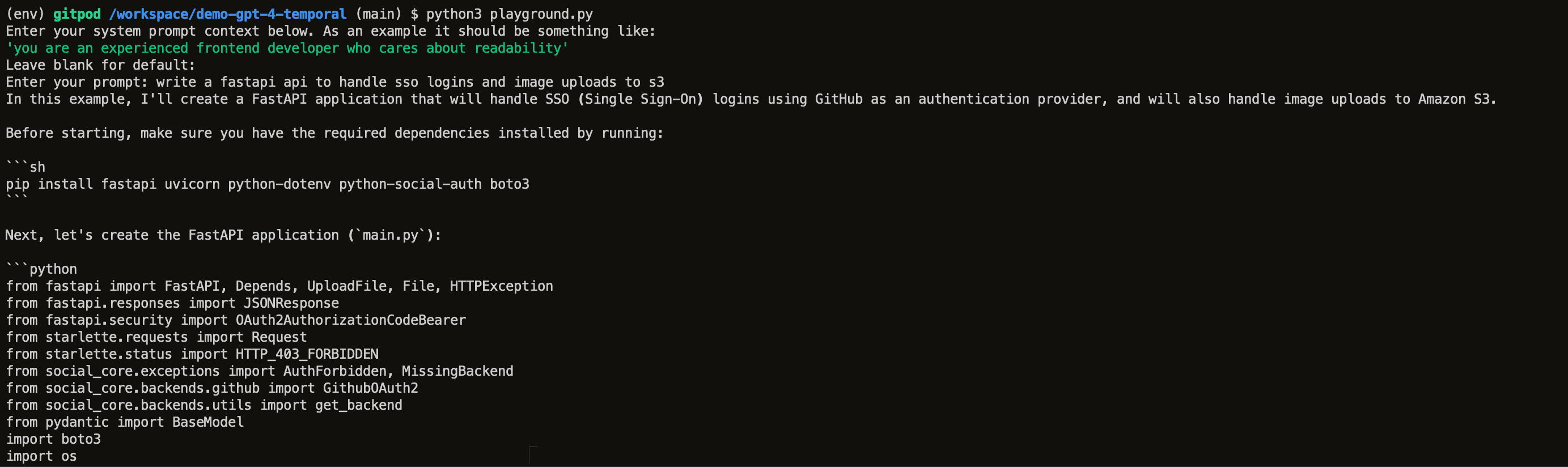
This is not quite production ready, but a great start to a project that would otherwise take time to set up.
In general, these large language models aren’t yet going to turn out perfect production code. It helps to be able to read the code afterwards, or to try running it in a disposable development environment before moving on.
So, what can we do to improve this? How can we turn it GPT-4 into a better software development tool?
Augmenting GPT-4’s Performance
Really, there are two main ways to enhance the performance of GPT-4. The first is via our prompts. Both the persona we ask GPT-4 to take on, and the type of question that we ask influence the quality of response. We must be explicit in our prompts so that GPT-4 uses the right part of it’s knowledge base to respond. So telling GPT-4 you want it to assume the role of an expert developer is critically important for good results.
This method of augmenting GPT-4 has been written very well by the Brex prompt engineering Github repository. I encourage you to read through that repository if you’re interested in a more sophisticated approach to your queries.
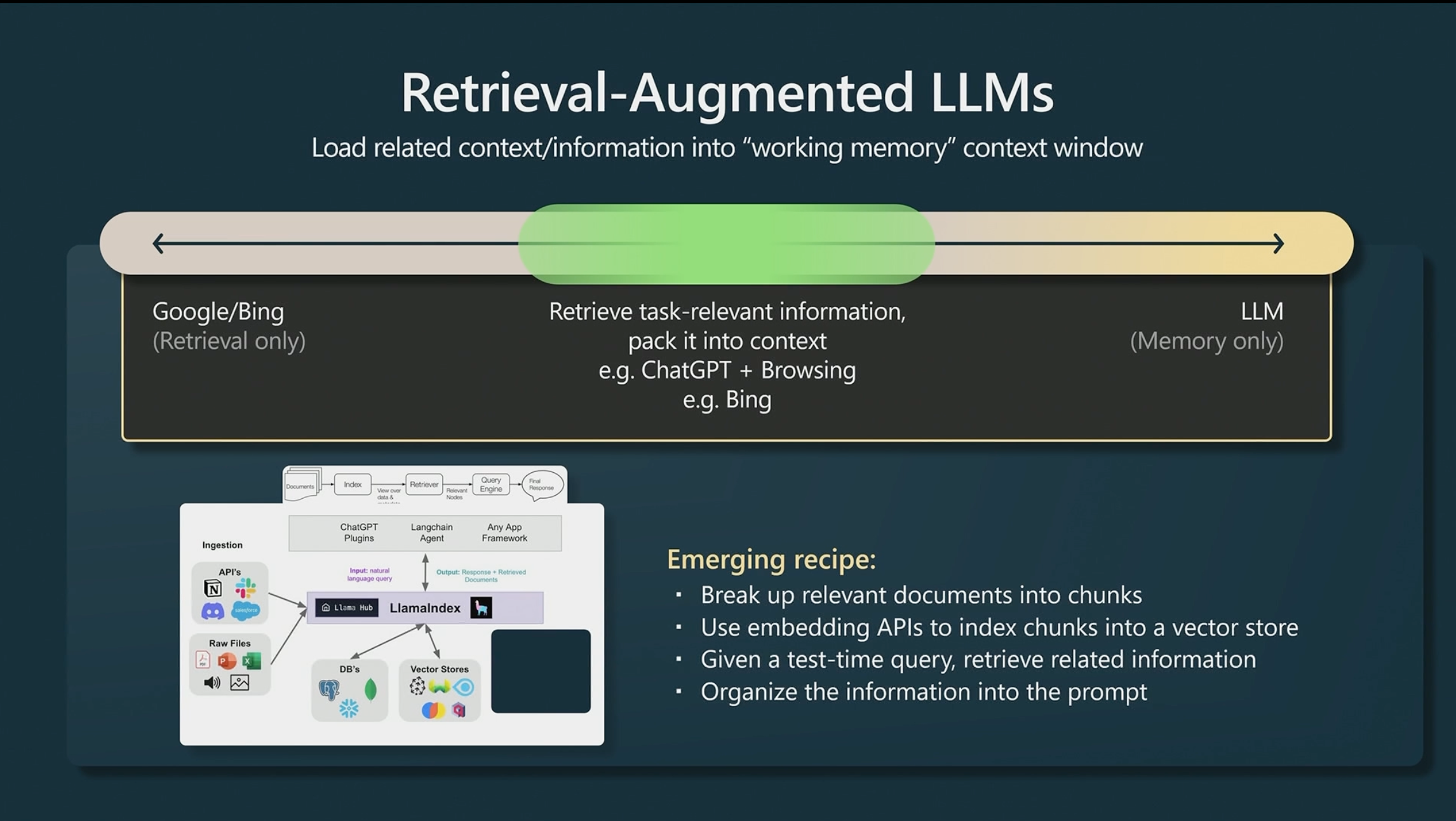
The other method of enhancing GPT-4’s responses is via augmenting our query with data that will help GPT-4 learn about the specific problem we’re facing. With this, we’d prepend relevant documents with context to our query to GPT-4, before asking our question.
For this post, we’ll mostly focus on the second sort of augmentation, adding in your custom data or context before posing your question.
So This Is Why Everyone Loves Vector Databases Now
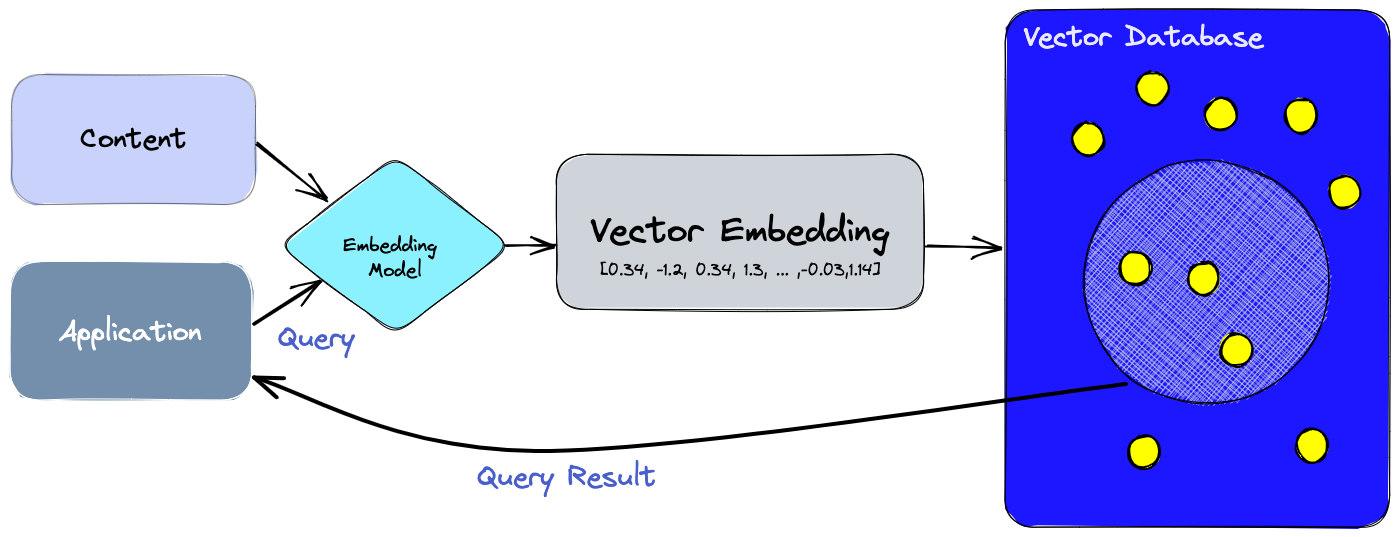
Vector databases have recently gained a lot of attention for their potential in augmenting large language models. The basic idea is to build a large database of relevant text snippets stored as embeddings, and to search through it when asking a question to a large language model.
Ideally, this resultant text is directly applicable to the question asked, or the task given to the language model. This resultant text is then injected before the question or task given to the language model, providing more context and specific information to base the answer off of.
We’ll use a Temporal workflow to scrape the documentation of Gitpod to build a vector database in this post, building up a knowledge base we can call upon to answer any questions we may have, or any tasks we may need done.
Building Knowledge Databases with Pinecone and Temporal Workflows
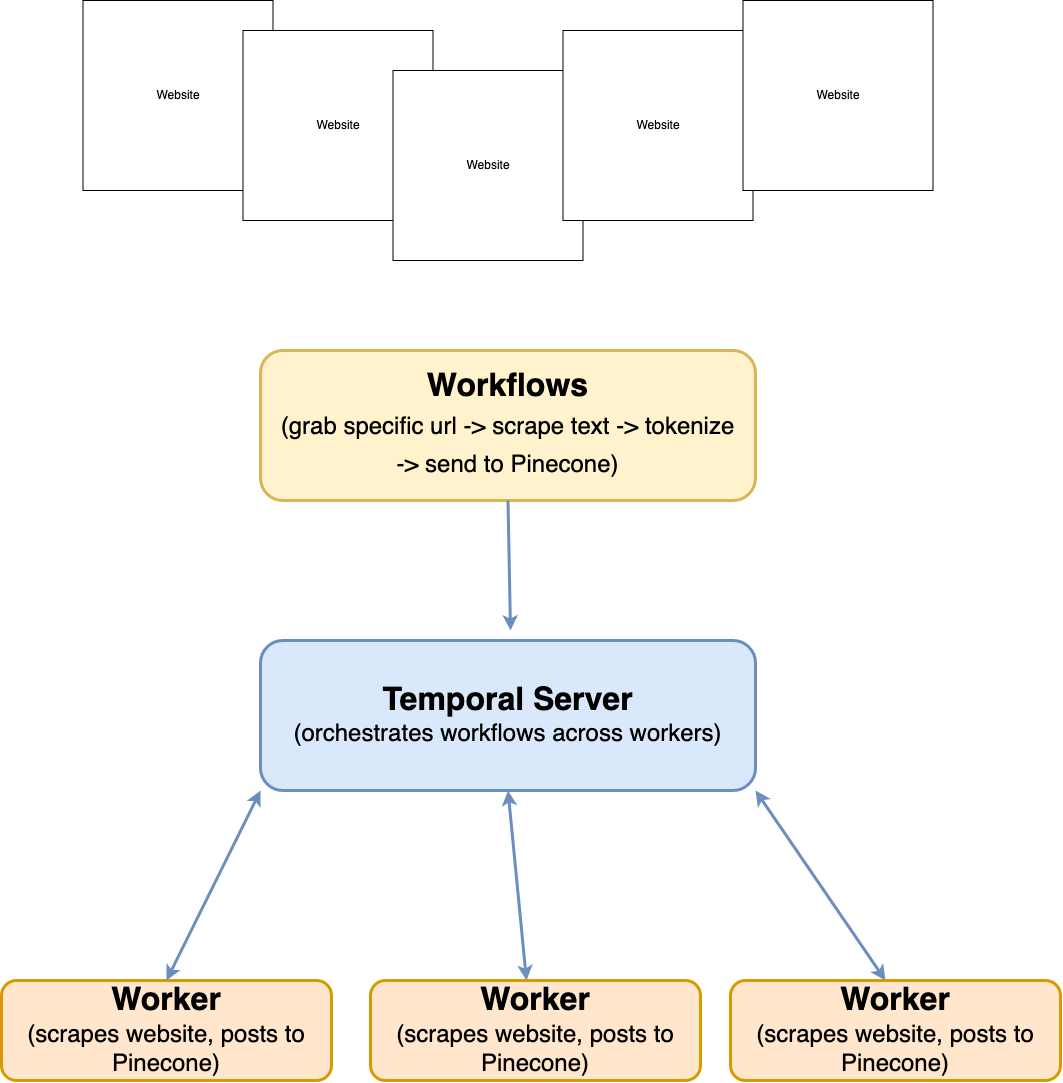
Temporal is a platform for orchestrating the running of workflows that may fail, in a way that the platform will automatically retry, deal with unreliable network connections, and resume from failed states.
Temporal is different from queues and workers in that it allows you to define your workflows mostly in code, and that it has exception handling, observability, and history built right in to the platform.
We’ll use a Temporal Workflow for the generation of an augmented dataset to query GPT-4 with.
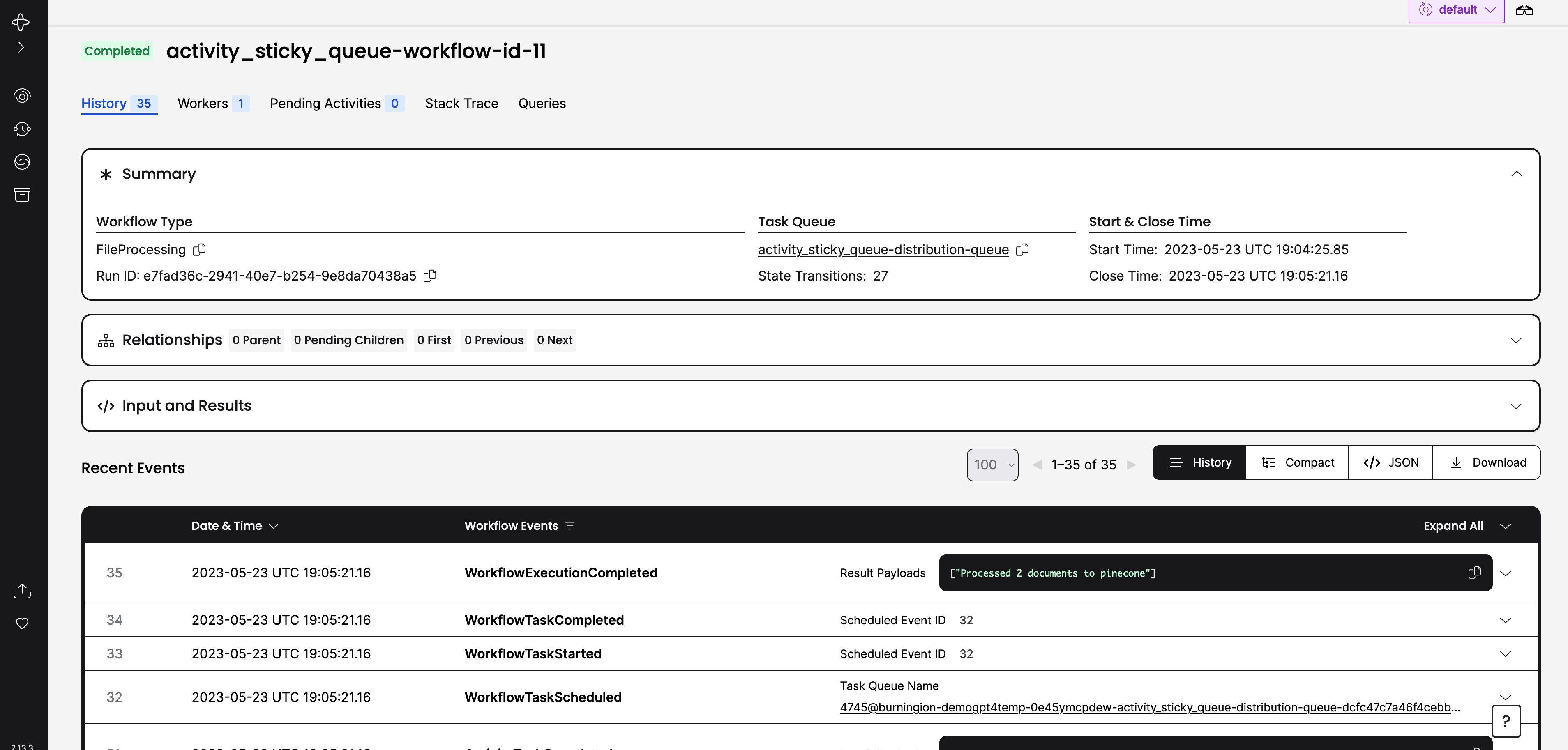
A Temporal Workflow will orchestrate the scraping of websites, stripping the webpages of HTML to basic text, and then finally converting the raw text to tokens, posting them to Pinecone to be added to a vector database index.
From there we’ll ready for search augmentation for our queries for GPT-4. Let’s jump in.
Orchestrating Pinecone Workflows in Gitpod with Temporal
The first thing we’ll need to do is build out a task.py file to define the task we’ll be running. We can think of Tasks as graphs on the compute that we need to run on our data. The big points that we need to focus on are the data types we’ll work with, and the first activity, to download a file to disk:
language: @dataclass
class DownloadObj:
url: str
unique_worker_id: str
workflow_uuid: str
@dataclass
class DownloadedObj:
url: str
path: str
@activity.defn
async def download_file_to_worker_filesystem(details: DownloadObj) -> str:
"""Downloads a URL to the local filesystem"""
path = create_filepath(details.unique_worker_id, details.workflow_uuid)
activity.logger.info(f"Downloading ${details.url} and saving to ${path}")
async with aiohttp.ClientSession() as sess:
async with sess.get(details.url) as resp:
# We don't want to retry client failure
if resp.status >= 400 and resp.status < 500:
raise ApplicationError(f"Status: {resp.status}", resp.json(), non_retryable=True)
# Otherwise, fail on bad status which will be inherently retried
with open(path, 'wb') as fd:
async for chunk in resp.content.iter_chunked(10):
fd.write(chunk)
return str(path)
Note that we’re using async here, so as not to block the overall execution of the Task. We can write out our other activities from here, adding an activity to read the file later, then delete it, and finally, orchestrate everything using a workflow definition:
language: @workflow.defn
class FileProcessing:
@workflow.run
async def run(self, url: str) -> str:
"""Workflow implementing the basic file processing example.
First, a worker is selected randomly. This is the "sticky worker" on which
the workflow runs. This consists of a file download and the text stripping to Pinecone,
with a file cleanup if an error occurs.
"""
workflow.logger.info("Searching for available worker")
workflow.logger.info(f"url: {url}")
unique_worker_task_queue = await workflow.execute_activity(
activity=get_available_task_queue,
start_to_close_timeout=timedelta(seconds=120),
)
workflow.logger.info(f"Matching workflow to worker {unique_worker_task_queue}")
download_params = DownloadObj(
url=url,
unique_worker_id=unique_worker_task_queue,
workflow_uuid=str(workflow.uuid4()),
)
download_path = await workflow.execute_activity(
download_file_to_worker_filesystem,
download_params,
start_to_close_timeout=timedelta(seconds=120),
task_queue=unique_worker_task_queue,
)
downloaded_file = DownloadedObj(url=url, path=download_path)
checksum = "failed execution" # Sentinel value
try:
checksum = await workflow.execute_activity(
work_on_file_in_worker_filesystem,
downloaded_file,
start_to_close_timeout=timedelta(seconds=120),
retry_policy=RetryPolicy(
maximum_attempts=2,
# maximum_interval=timedelta(milliseconds=500),
),
task_queue=unique_worker_task_queue,
)
finally:
await workflow.execute_activity(
clean_up_file_from_worker_filesystem,
download_path,
start_to_close_timeout=timedelta(seconds=120),
task_queue=unique_worker_task_queue,
)
return checksumWith this, we mostly have our stub to execute the downloading of HTML. Next, convert our raw HTML to plain text, and then tokenize them, then finally, upload those tokens to Pinecone.
From Scraped Raw HTML to Tokenized Chunks of Text
OpenAI has a great example application showcasing retrieval augmentation with Pinecone.
We’ll mostly base our scraping off of their work, with the minor change of not using the ReadTheDocs interpreter from Langchain, but instead using the BeautifulSoup HTML reader. The helper function to convert our downloaded HTML to raw text looks like this:
language: def read_file(path, url) -> list:
"""Read file and load with BS4"""
loader = BSHTMLLoader(path)
data = loader.load()
plain_text = []
for i in range(len(data)):
a = data[i]
plain_text.append({"text": a.page_content,
"source": url})
return plain_textYou’ll notice we’ve converted the page to a dictionary containing the keys text and source. The source key allows us to keep the webpage as a reference in our response.
Next, we’ll need to convert this text into tokens for OpenAI to read, and for Pinecone to search:
language: def process_file_contents(file_content: list) -> str:
"""split, create embeddings, and post to pinecone"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""]
)
chunks = []
for idx, record in enumerate(tqdm(file_content)):
texts = text_splitter.split_text(record['text'])
chunks.extend([{
'id': str(uuid4()),
'text': texts[i],
'chunk': i,
'url': record['source']
} for i in range(len(texts))])
openai.api_key = os.environ['OPENAI_API_KEY']
embed_model = "text-embedding-ada-002"
index_name = os.environ['PINECONE_INDEX']
pinecone.init(
api_key=os.environ['PINECONE_API_KEY'], # app.pinecone.io (console)
environment=os.environ['PINECONE_ENVIRONMENT'] # next to API key in console
)
res = openai.Embedding.create(
input=[
"Sample document text goes here",
"there will be several phrases in each batch"
], engine=embed_model
)
# check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
index_name,
dimension=len(res['data'][0]['embedding']),
metric='dotproduct'
)
# connect to index
index = pinecone.GRPCIndex(index_name)
batch_size = 100 # how many embeddings we create and insert at once
for i in tqdm(range(0, len(chunks), batch_size)):
# find end of batch
i_end = min(len(chunks), i+batch_size)
meta_batch = chunks[i:i_end]
# get ids
ids_batch = [x['id'] for x in meta_batch]
# get texts to encode
texts = [x['text'] for x in meta_batch]
# create embeddings (try-except added to avoid RateLimitError)
res = openai.Embedding.create(input=texts, engine=embed_model)
embeds = [record['embedding'] for record in res['data']]
# cleanup metadata
meta_batch = [{
'text': x['text'],
'chunk': x['chunk'],
'url': x['url']
} for x in meta_batch]
to_upsert = list(zip(ids_batch, embeds, meta_batch))
# upsert to Pinecone
index.upsert(vectors=to_upsert)
return f"Processed {len(chunks)} documents to pinecone"This is a lot to take in, and should probably be broken up. But let’s take the function in pieces:
language: text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""]
)
chunks = []We need to ensure our tokenized text fits within the windows available for reading. Here we’ve set a chunk_size for each chunk of text, along with an overlap in characters.
Next, we need to iterate on the text we have, breaking up the text into chunks:
language: for idx, record in enumerate(tqdm(file_content)):
texts = text_splitter.split_text(record['text'])
chunks.extend([{
'id': str(uuid4()),
'text': texts[i],
'chunk': i,
'url': record['source']
} for i in range(len(texts))])This splits up our text into chunks that fit as entries within our vector database, getting them ready actually be inserted into Pinecone.
Next, we configure OpenAI and Pinecone, getting them ready for upsertion / tokenization:
language: openai.api_key = os.environ['OPENAI_API_KEY']
embed_model = "text-embedding-ada-002"
index_name = os.environ['PINECONE_INDEX']
pinecone.init(
api_key=os.environ['PINECONE_API_KEY'], # app.pinecone.io (console)
environment=os.environ['PINECONE_ENVIRONMENT'] # next to API key in console
)
res = openai.Embedding.create(
input=[
"Sample document text goes here",
"there will be several phrases in each batch"
], engine=embed_model
)
# check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
index_name,
dimension=len(res['data'][0]['embedding']),
metric='dotproduct'
)
# connect to index
index = pinecone.GRPCIndex(index_name)
batch_size = 100 # how many embeddings we create and insert at onceNote that we’re expecting environment variables to be set here, which will ensure that we authenticate with both Pinecone and OpenAI properly.
Finally, we tokenize our text, and insert to Pinecone:
language: for i in tqdm(range(0, len(chunks), batch_size)):
# find end of batch
i_end = min(len(chunks), i+batch_size)
meta_batch = chunks[i:i_end]
# get ids
ids_batch = [x['id'] for x in meta_batch]
# get texts to encode
texts = [x['text'] for x in meta_batch]
# create embeddings (try-except added to avoid RateLimitError)
res = openai.Embedding.create(input=texts, engine=embed_model)
embeds = [record['embedding'] for record in res['data']]
# cleanup metadata
meta_batch = [{
'text': x['text'],
'chunk': x['chunk'],
'url': x['url']
} for x in meta_batch]
to_upsert = list(zip(ids_batch, embeds, meta_batch))
# upsert to Pinecone
index.upsert(vectors=to_upsert)
return f"Processed {len(chunks)} documents to pinecone"With this, we’re ready to run our workflow on a set of URLs, and populate our vector database with the tokens / embeddings.
Running A Temporal Workflow
To run our Temporal workflow to insert these tokens, we’ll need be running Temporal in our development environment. The repository already has this configured.
For that, our .gitpod.yml file can ensure we’ve got a running system:
language: image:
file: .gitpod.Dockerfile
vscode:
extensions:
- ms-python.isort
- ms-python.python
- charliermarsh.ruff
tasks:
- name: OpenAI Chat Interface
command: pip install -r requirements.txt && python3 interactive-playground.py
- name: Temporal Dev Env
command: python -m venv env && source env/bin/activate && pip install -r src/requirements.txt && cd src/
- name: Temporal Dev Server
command: temporal server start-dev
ports:
- port: 8233
onOpen: open-preview
name: Temporal FrontendNot specified within this .gitpod.yml, is the enviornment variables we’ll need to set before we can run our applicaton.
We can set environment variables for our OpenAI key, Pinecone API key, Pinecone datacenter name, and Pinecone index name in the variables setting of our Gitpod account.
Note for our application that we’ve got multiple Gitpod tasks running here. There’s a Temporal Dev Env, and a Temporal Dev Server. The Dev Env allows us to run our Workers, while the Server runs the Temporal server itself.
Once the Gitod workspace is spun up, we can start the workers with a:
language: $ python3 worker.pyThis will start the worker processes. You can then create a new bash terminal, leaving that process running.
Our Workers need work to execute, and for that, we’ll need to send work to the workers with the following:
language: $ python3 starter.pyThis will add jobs to the Temporal queue, using the list of URLs at the beginning of the file. Change them to edit your knowledge base.
Testing our Pinecone Augmented Results
Finally, once we’ve run our commands we can try querying our Pinecone database ahead of a query to GPT-4. The program is relatively straightforward:
language: import pinecone
import openai
import os
import pprint
from rich import print
pp = pprint.PrettyPrinter(indent=2)
openai.api_key = os.environ['OPENAI_API_KEY']
embed_model = "text-embedding-ada-002"
index_name = os.environ['PINECONE_INDEX']
pinecone.init(
api_key=os.environ['PINECONE_API_KEY'], # app.pinecone.io (console)
environment=os.environ['PINECONE_ENVIRONMENT'] # next to API key in console
)
index = pinecone.GRPCIndex(index_name)
query = input("Enter your question to be augmented: ")
res = openai.Embedding.create(
input=[query],
engine=embed_model
)
# retrieve from Pinecone
xq = res['data'][0]['embedding']
# get relevant contexts (including the questions)
res = index.query(xq, top_k=5, include_metadata=True)
pp.pprint(res)
contexts = [item['metadata']['text'] for item in res['matches']]
augmented_query = "\n\n---\n\n".join(contexts)+"\n\n-----\n\n"+query
# system message to 'prime' the model
primer = f"""You are Q&A bot. A highly intelligent system that answers
user questions based on the information provided by the user above
each question. If the information can not be found in the information
provided by the user you truthfully say "I don't know".
"""
res = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": primer},
{"role": "user", "content": augmented_query}
]
)
print(res["choices"][0]["message"]["content"])We can now try executing our questions with and without our context, to confirm that we’re actually improving the results coming back from GPT-4:
Prompt: write a single .gitpod.yml file for a fastapi python project. the application is named
main.py, and the command to run it isuvicorn main:app --host 0.0.0.0 --port 8000. the other library dependencies are fastapi uvicorn python-dotenv python-social-auth boto3. be sure to explain your work
Response:
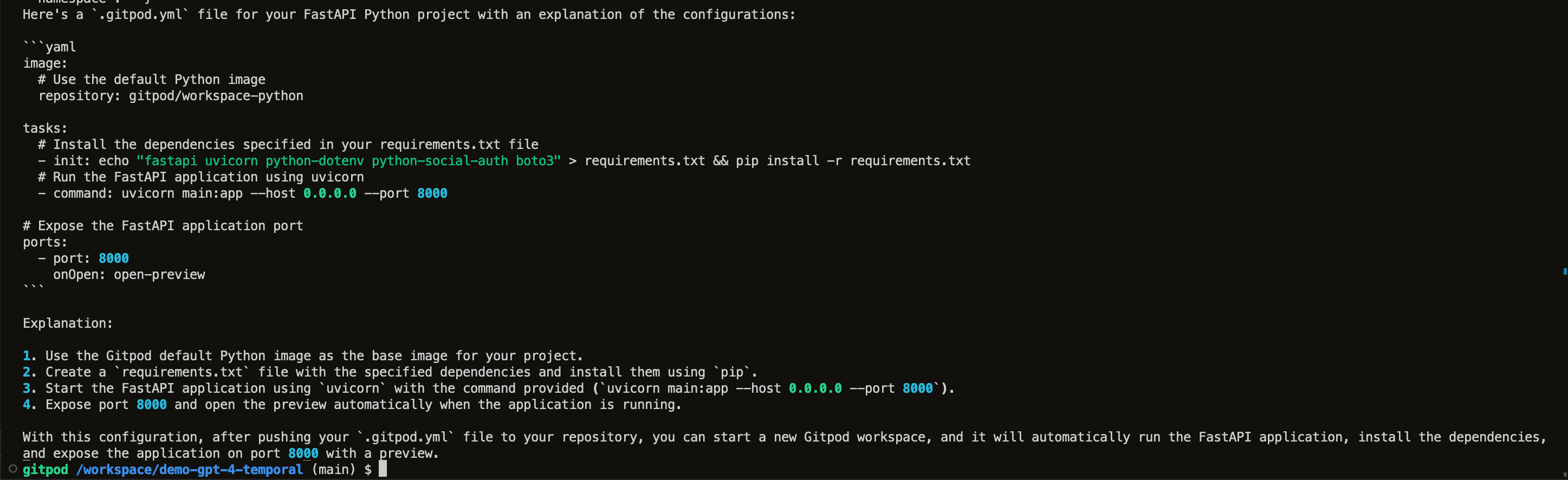
This works! The generated .gitpod.yml actually runs our repository straight out of the prompt with only the minor change of the erroneous (hallucinated?) repository tag.
Removing it and keeping the image: gitpod/workspace-python means we have a working environment for our generated code.
Extending the Workflow Platform
As written, the Github repository still has room for improvements. I encourage you to try it out.
For starters, here are a few ideas to pursue:
- Scrape the documentation of all the libraries you use for development. Use these documents to build up a better query system, maybe even pinning documentation version numbers to the numbers in your
requirements.txt. - Add a language model running locally on your computer to do the query. You can use Tailscale and add your home machine as a node, and then connect via a Gitpod workspace as an ephemeral node.
- Refine the feedback loop for augmented queries. Pick a token window size and determine a smart way to fit the right amount of context for interactive conversations. There’s a started file in the repo to bootstrap from.
- Use LoRA to fine tune your own language model, using Temporal’s workflows to build your data pipeline.
I’m excited to see what you build, please don’t hesitate to share with me on Twitter.
Share this post


